
Earth Engine Community Exchange: How I Built an AI-Powered Archive of Community Discussions
How freeing GEE discussions from Google Groups allowed helping build a community commons data exchange. Prototyping search and summary from last 5 years of GEE Discussions

Over the next couple of articles I am hoping to write about products I am building around the Google Earth Engine Ecosystem, or platforms that never quite evolved into the feature-rich systems the community actually needed. The applications I am building are designed to be prototypes things I can build and test and redo as needed and feature sets I wish existed as I have heard from feedback over the years and I hope others to build their own versions of projects. Some may remain experiments. Others I hope to open-source entirely, allowing individuals, labs, or research teams to deploy their own versions with minimal effort.
For the first project I have decide to create something that I always wishes existed with Google Earth Engine Community. For more than a decade, much of the institutional knowledge around Earth Engine has lived inside a single sprawling Google Group. If you’ve spent enough time in the ecosystem, you know the place well: thousands of troubleshooting threads, obscure workflows, half-documented techniques, clever workarounds, arguments over projections, and the occasional brilliant answer hidden six replies deep in an email chain from 2017. Now I know that a lot of this might be outdated but its still community discussions and knowledge that is meaningful just to see how we collectively solve problem and share insights. But searching in Google Groups using keyword search is far what what you would expect in 2026 or even earlier.
Mix this with a nostalgia for Community Commons like Stack Exchange or what it used to be and other places where users would answer questions along with each other I decided to build a Earth Engine community exchange. So here’s the thing, the google group is public but connecting AI to google groups would be a hard challenge since users don’t have those rights and scraping google groups is a non trivial tasks.

So I did the next best thing possible, all google groups depending on your notification setting also not controlled by us but by the team at Earth Engine gets notified of every conversation in an email thread. And guess what emails are easy to export in bulk and programmatically. So this all starts with exporting emails from Jan 2021 to Jan 2026 as a proof of concept to capture about 5 years and over 13500+ emails with the same discussions and threads to get this done. In many ways, that archive is the community memory of Earth Engine.
Building the Backend
Right off the bat let me tell you this for me to host this locally I needed a GPU but you can do this using embedding models and frontier models hosted online like Gemini using their API keys. I wanted to host this locally because I didn’t want to worry about costs of experimenting with this but also this was something I could build and experiment using different models. This could be more dense that I want it to so I am keeping it short. TLDR this uses Qwen3 8B model which is small and yet powerful enough for doing the type of summarization needed for the users against such a database. This is effectively an community knowledge RAG or Retrieval Augmented Generation application and for now this is not accessible to other users but I can probably come up with a plan to serve others in the future.

So lets talk architecture, the system relies on us writing the emails to a database which can be appended so I chose SQLite for that and yes you can choose something else. Since I was deploying this for ease it meant not need a backend service to just run this and also I can package the database and just provide it to other users for use or just bundle it up in a docker container so you don’t have to download your emails and so on. There are many other components but the embedding model I am using is bge-m3 which is one of the state of the art models out there. What this does is chunking and then converting these texts into a sort of a lookup directory. When a user asks a question the system converts this into something the lookup directory understands and retrieves the relevant conversations and then finally the Large Language Model (LLM) summarizes the results into something that reads like an answer. Now I know some of you might have suggestions for better models and retrieval and reranknig systems, as you can imagine I chose what felt like a good use for my hardware while keeping it light
What can you do with this?
So yeah sure that sounds fun and does it leave you wondering why this doesn’t exist? I am not sure of the reasons but am glad this was fun to build because of exactly this. So what can it do? Again you will see some obvious one that I took inspiration from Stack Exchange. You can filter using keywords those that were the top topics across discussions you can filter using these to know what did most people discuss about and read the entire thread like I said there is scoring of sorts. And there is categories where I asked it to rank if something has code or has been answered or so on. It’s not 100% accurate but its great for what I need.
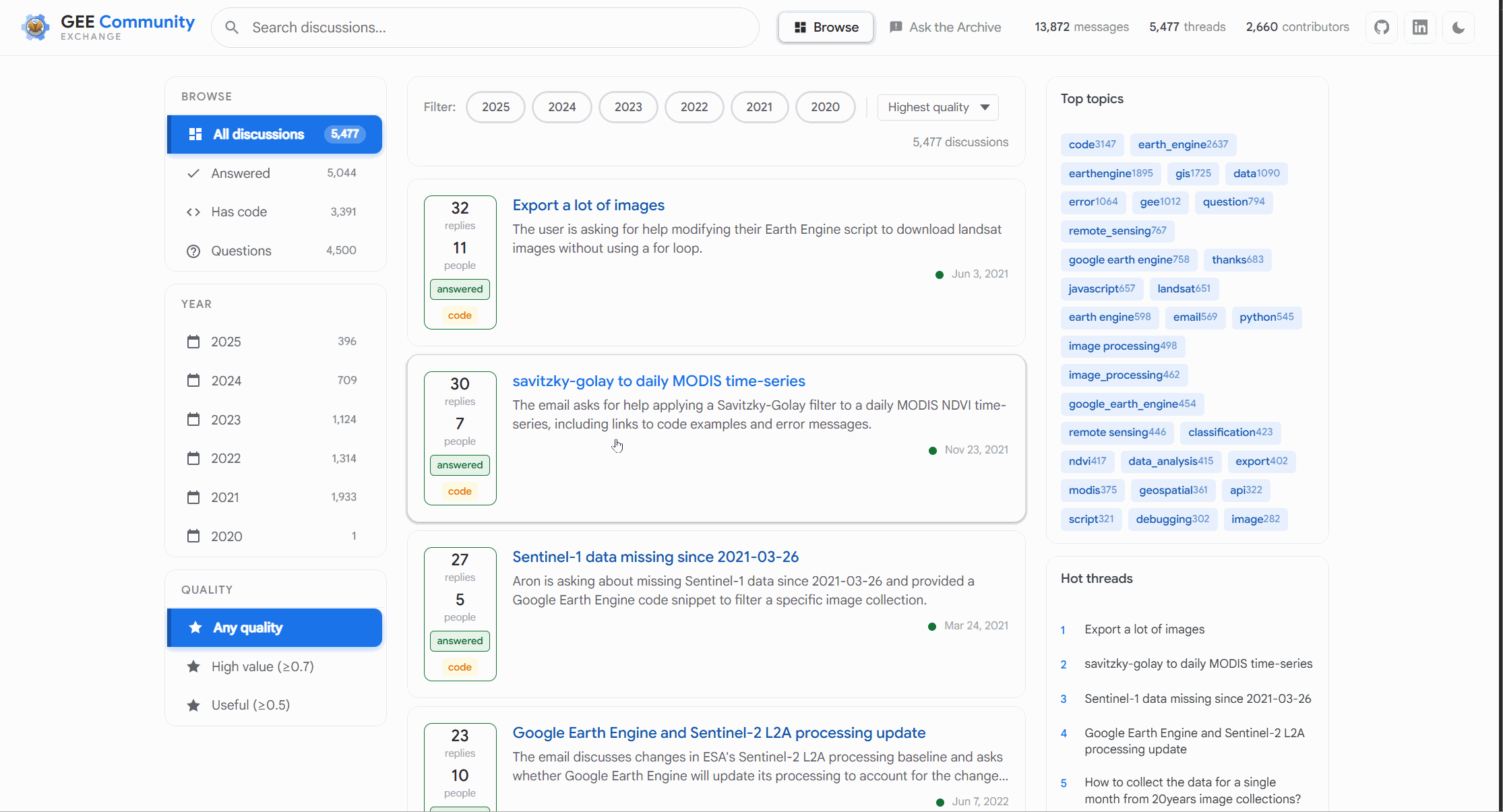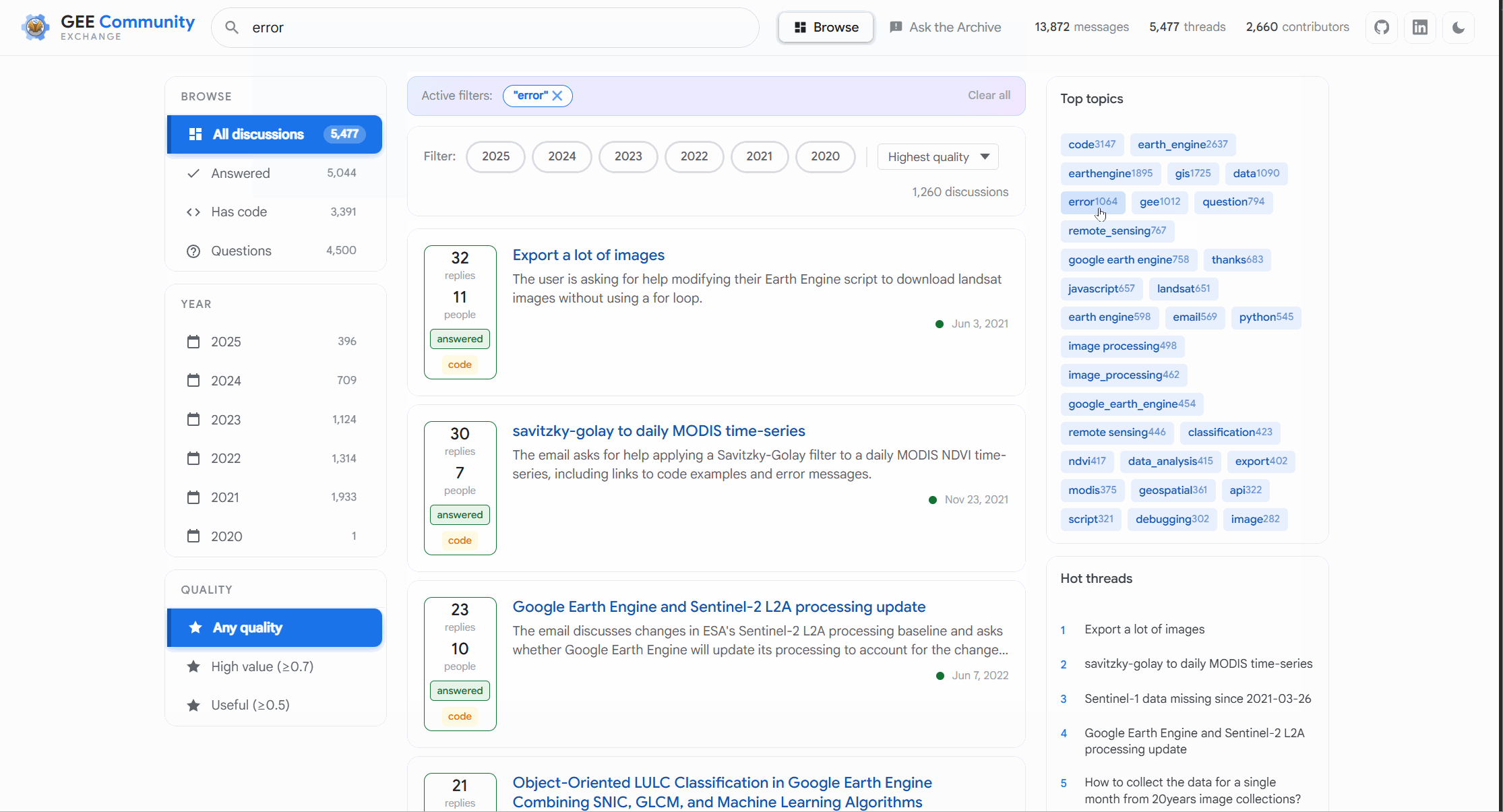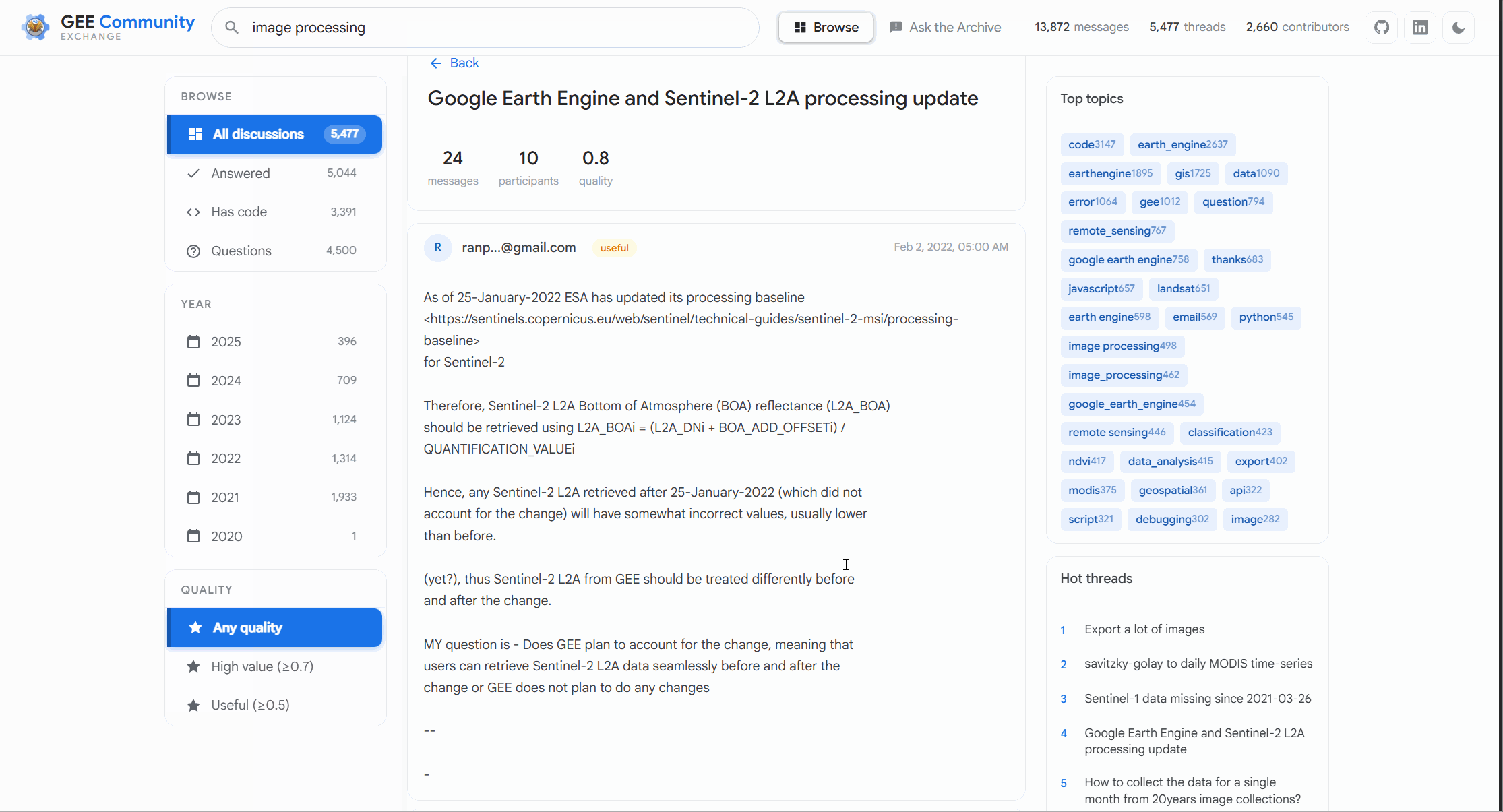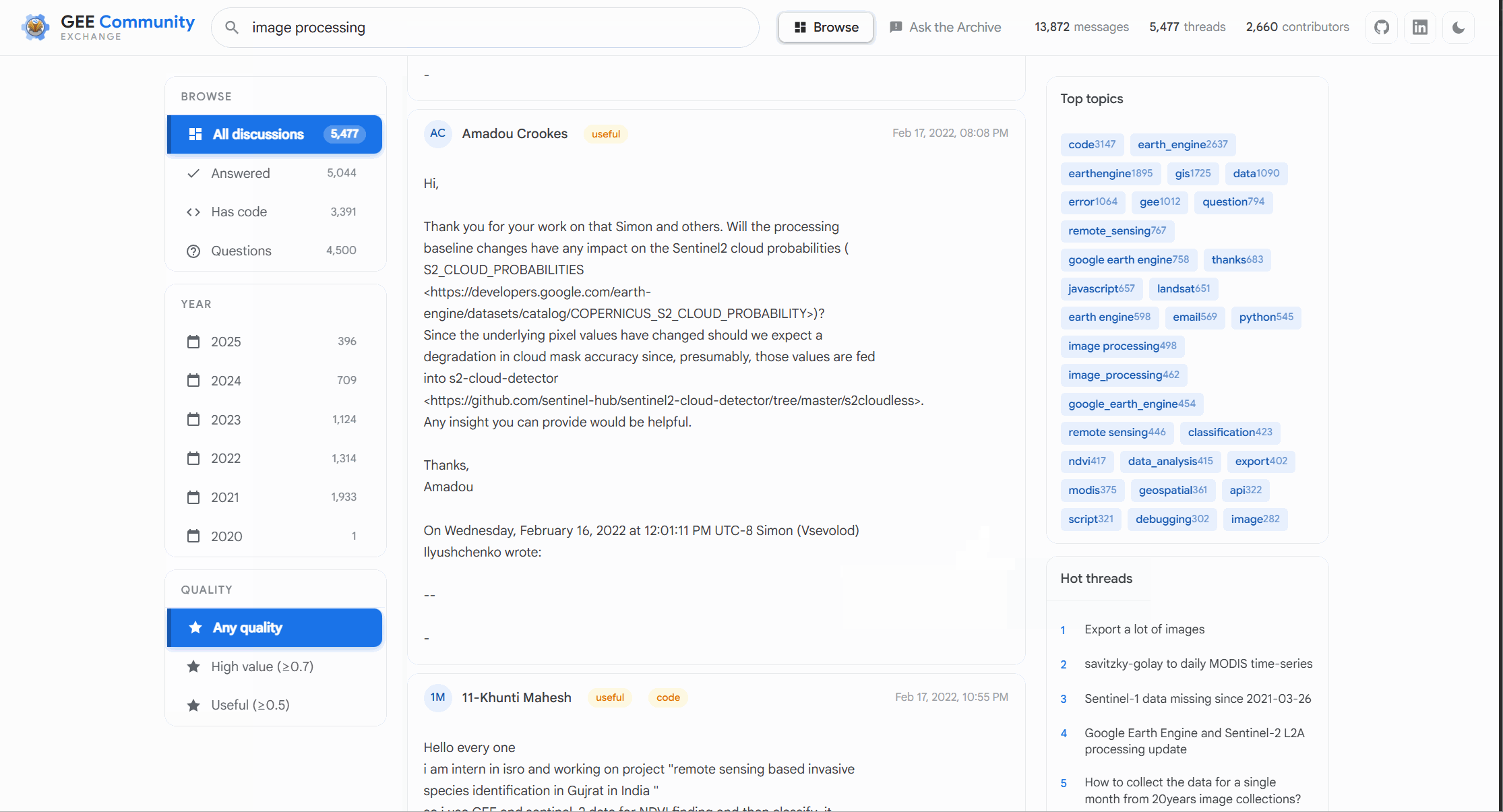
Not to mention you can do a quick search using keywords first. This is similar to how you could already do search and it can handle some basic phrases too
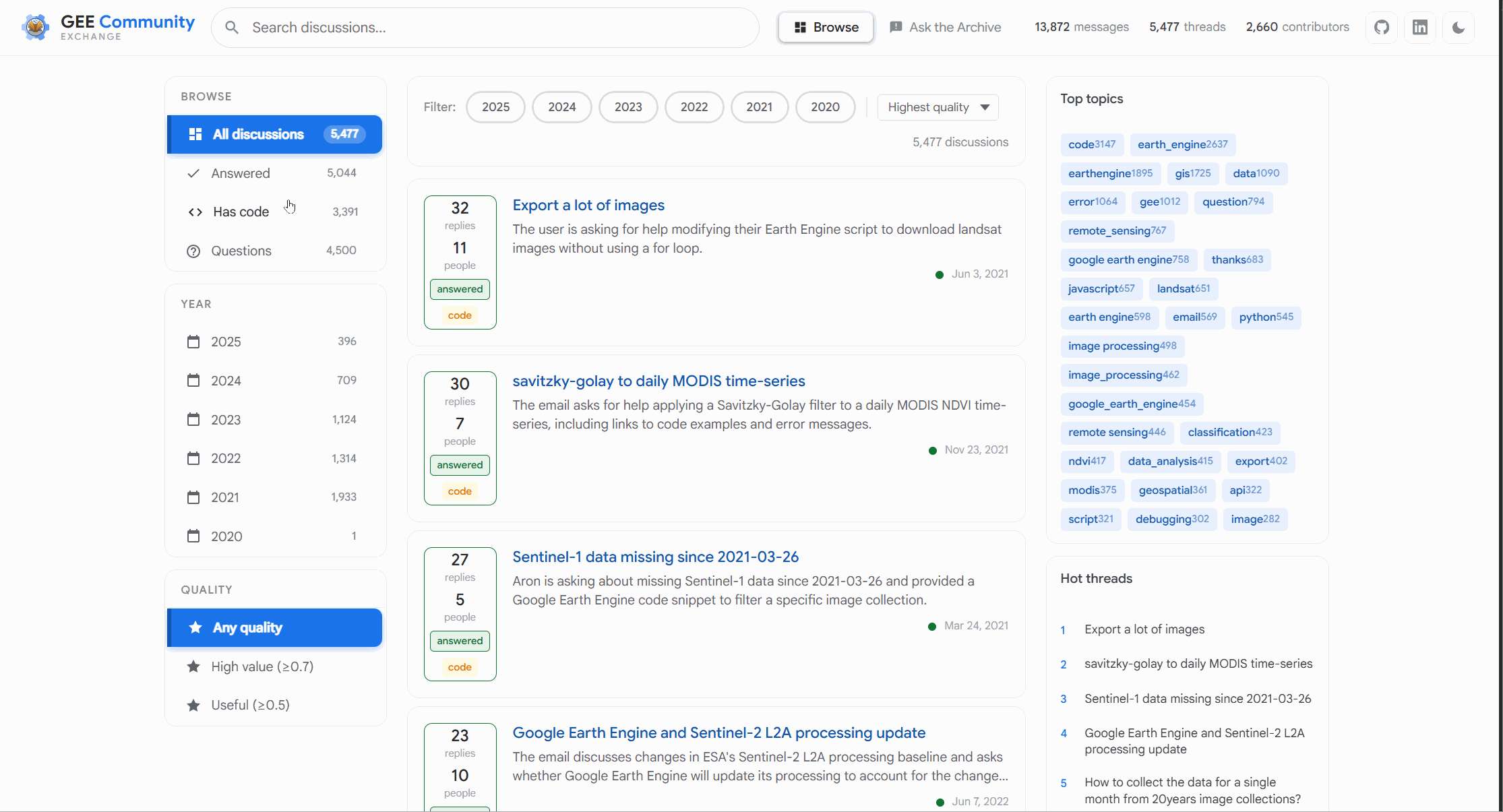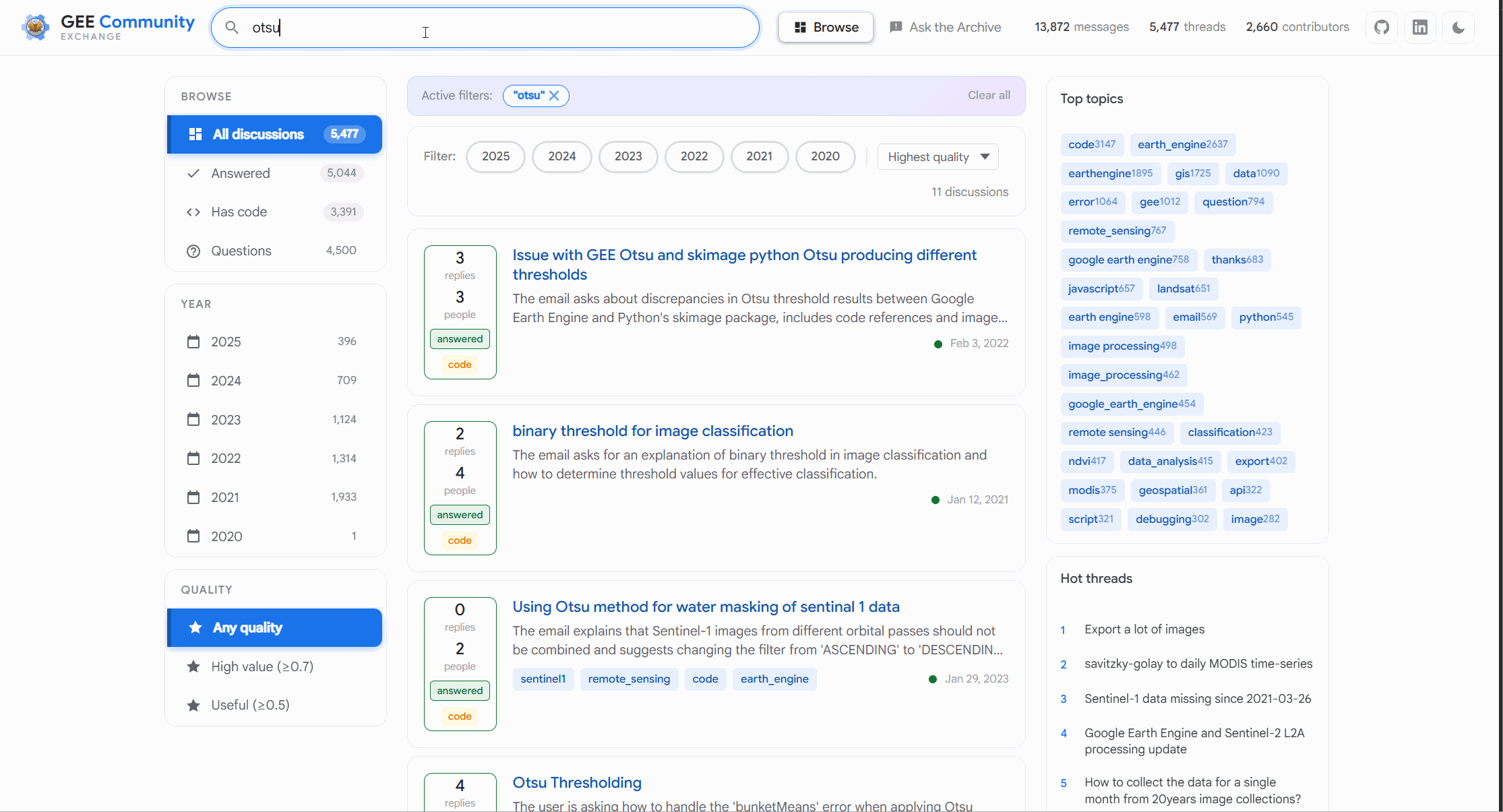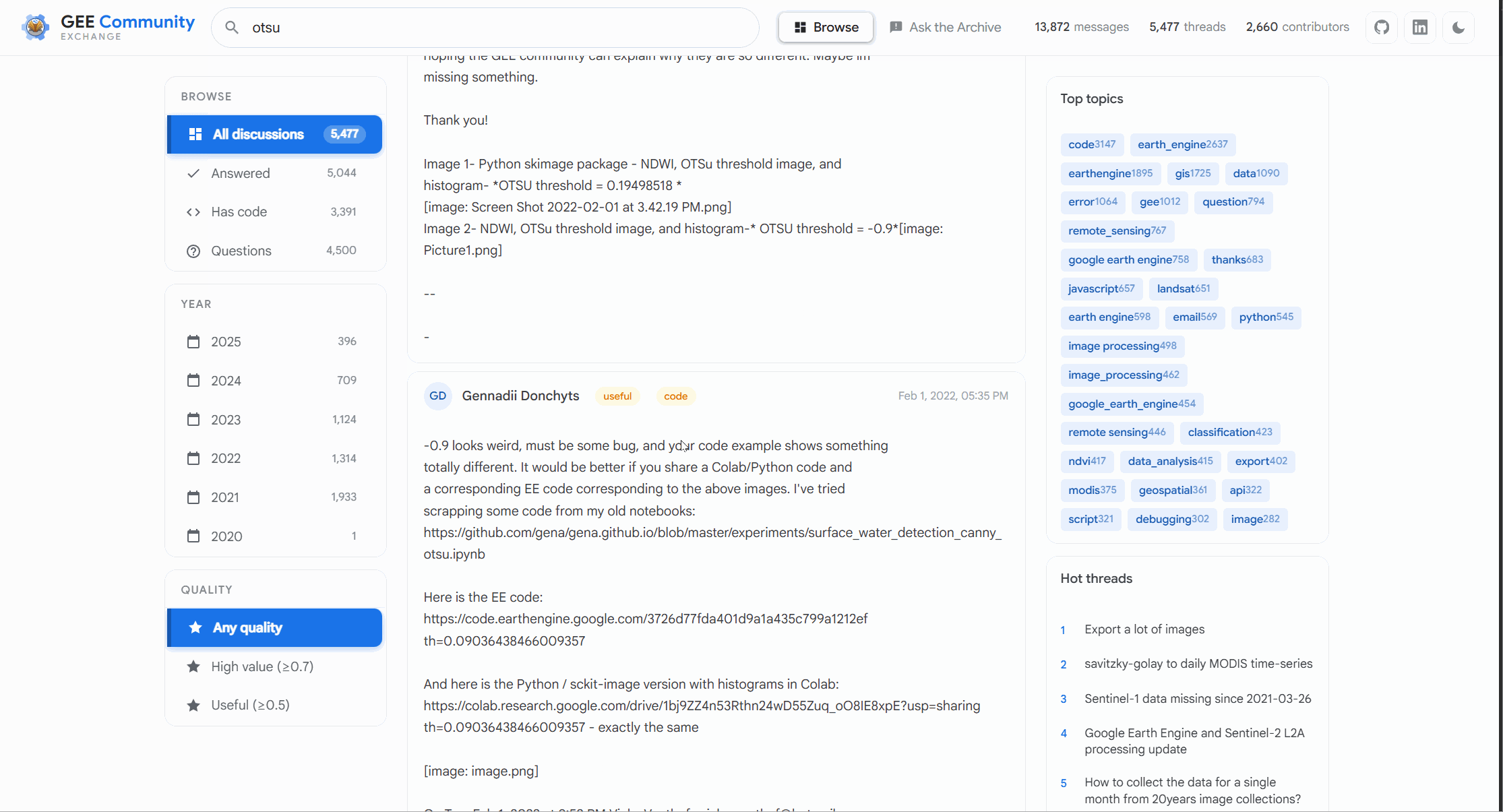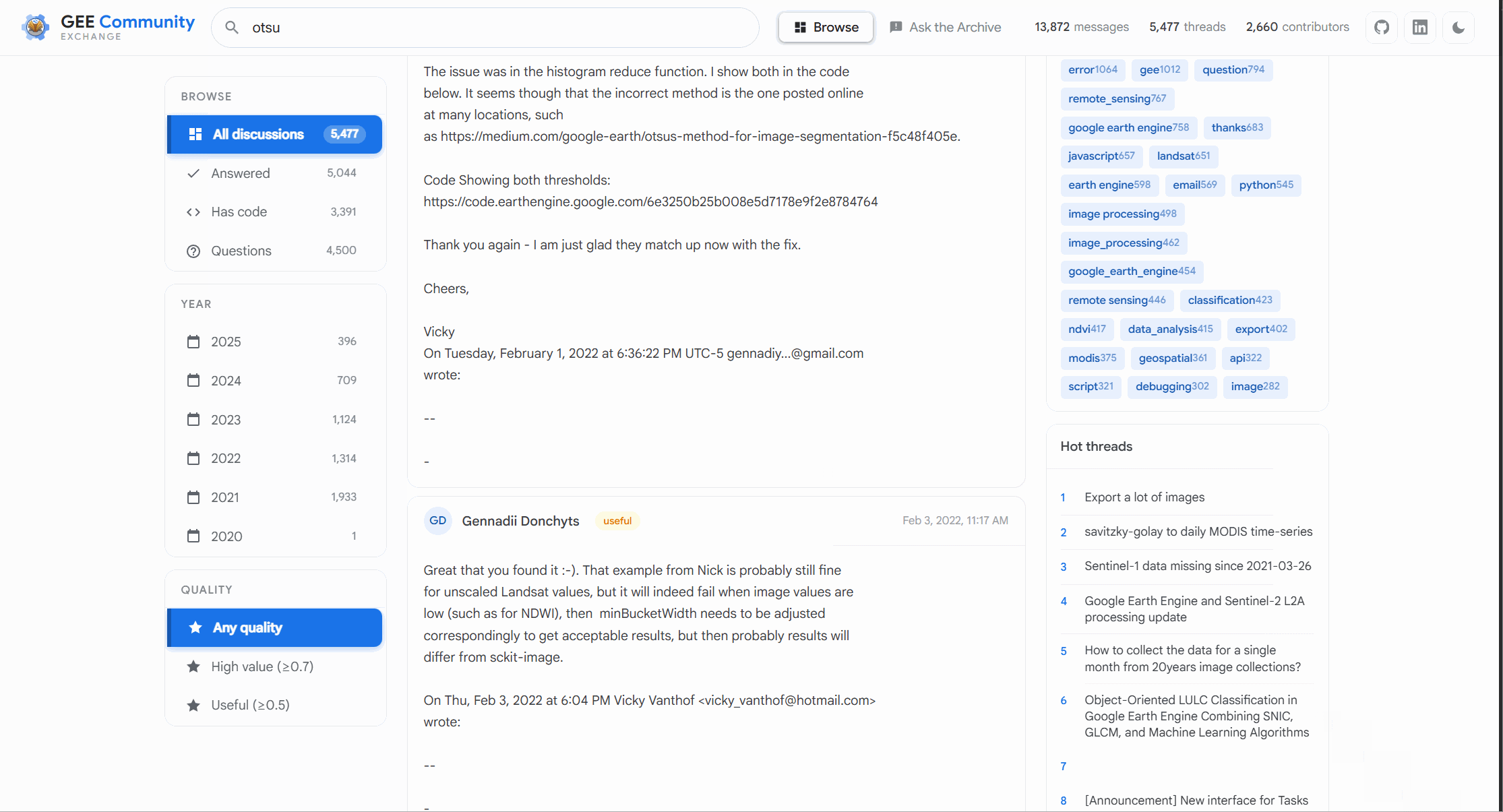
This allows you to look at each conversation including looking at tags we have added to some conversations where it was obvious. The search allows you to find the conversation clicking on it maintains the traces and dates and all the fun bits we have in conversation land. But you didn’t come for basic search
Ask the Archive: Building the AI powered Search
So we have taken and built out the quick keyword search and you can use those across the 13,500+ conversations and the responsiveness is great sub second in most cases. Build the next bit was the fun one , building the Ask the Archive functionality and yes this is powered by the LLM in the backend. This is where you can ask a long form natural language question and the system retrieves the relevant discussion and sources the answer from there. This was the cherry on top the reason to build this in the first place
Instead of searching for fragments of text, you can ask the archive a full natural-language question:
Why do Earth Engine exports fail when mosaicking Sentinel-2 imagery at large scales?
Or:
What approaches have people used for temporal interpolation in sparse MODIS datasets?
The system retrieves the most relevant historical discussions, pulls together the surrounding context, and synthesizes an answer grounded in years of community conversations. Since it needs to fetch an actual conversation for source it does not hallucinate to a large degree.
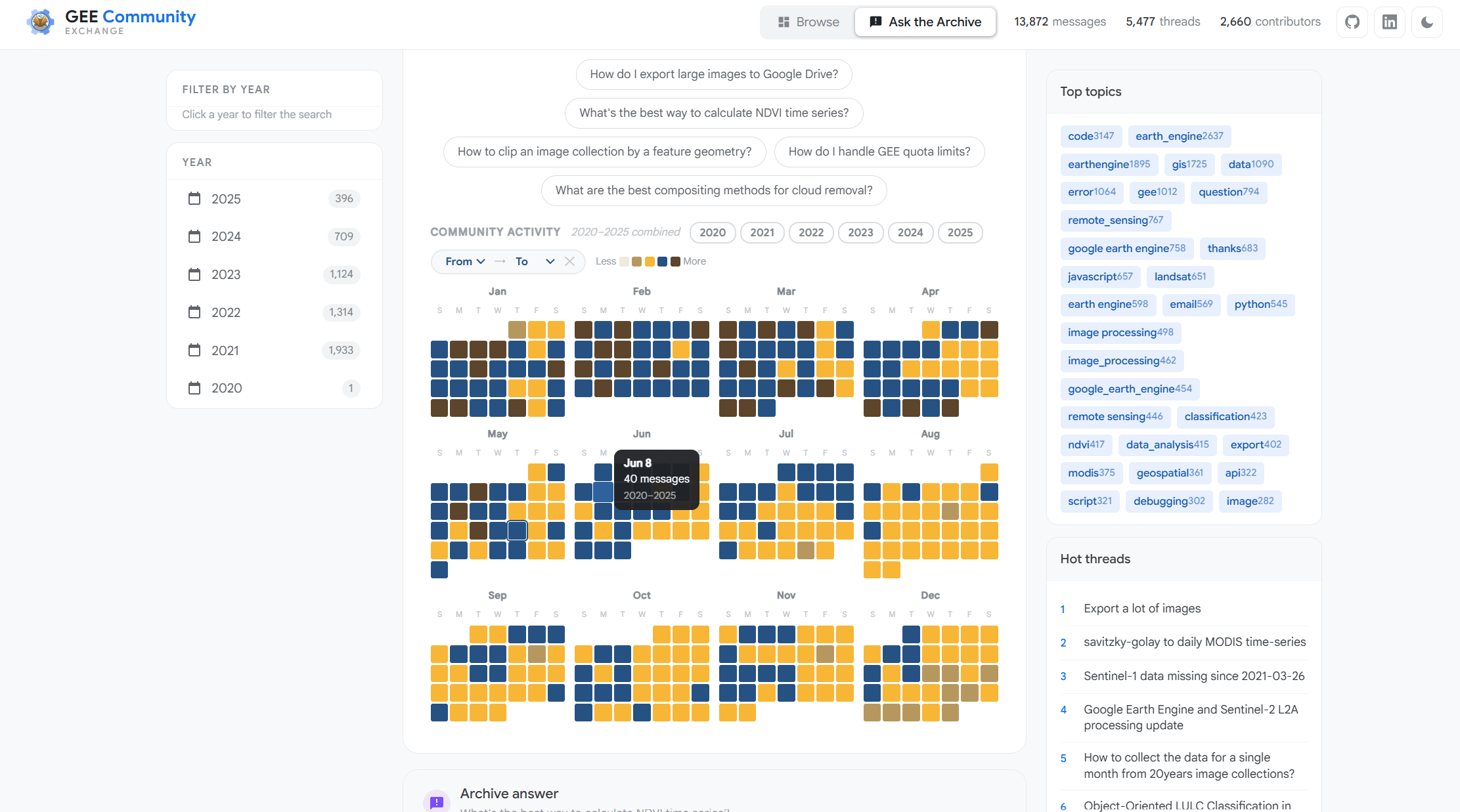
And yes I love seeing was there days across the many years that users were most active with discussions and questions so this can give you a quick look at how many messages on that day over the last 5 years.
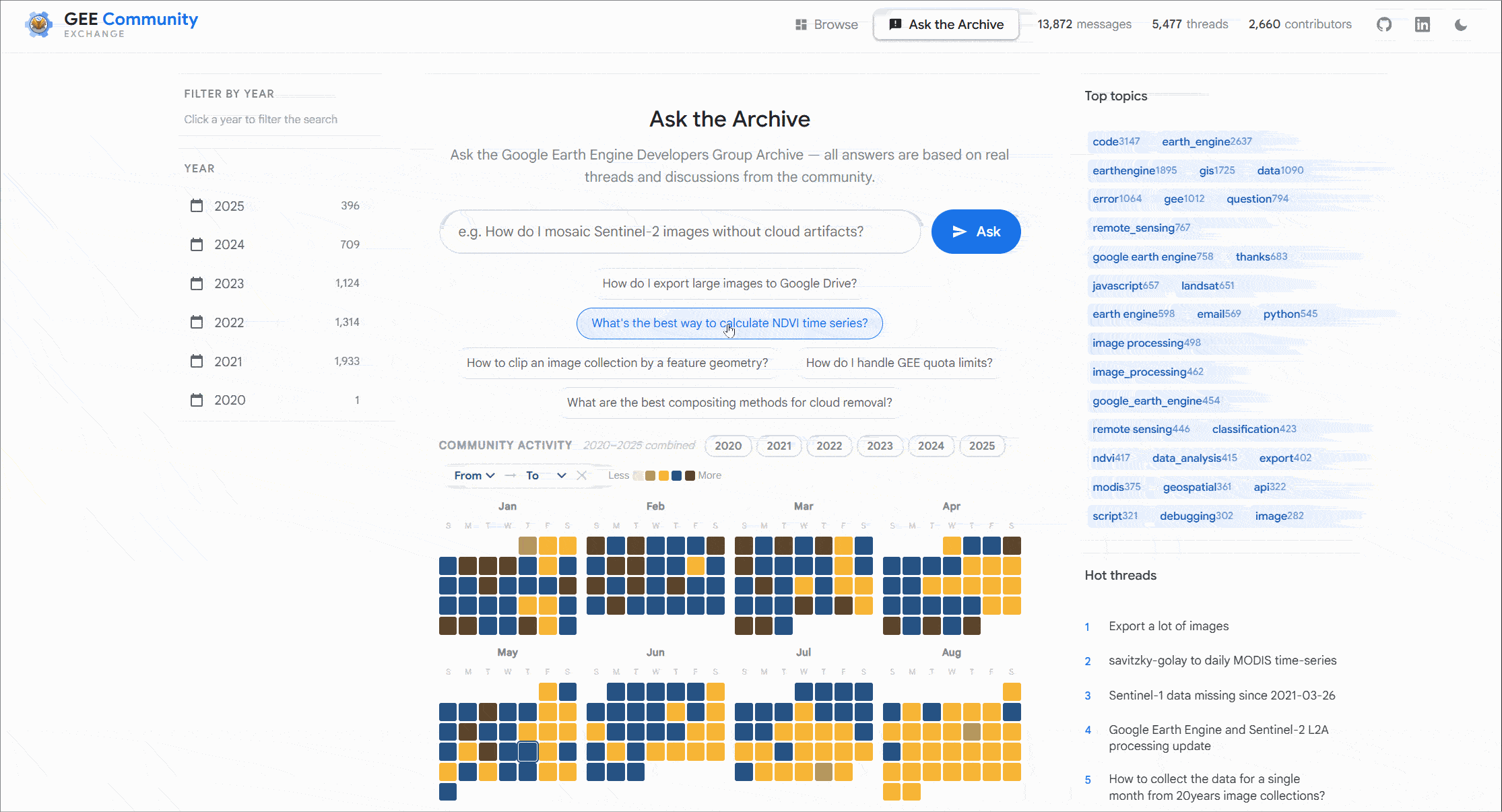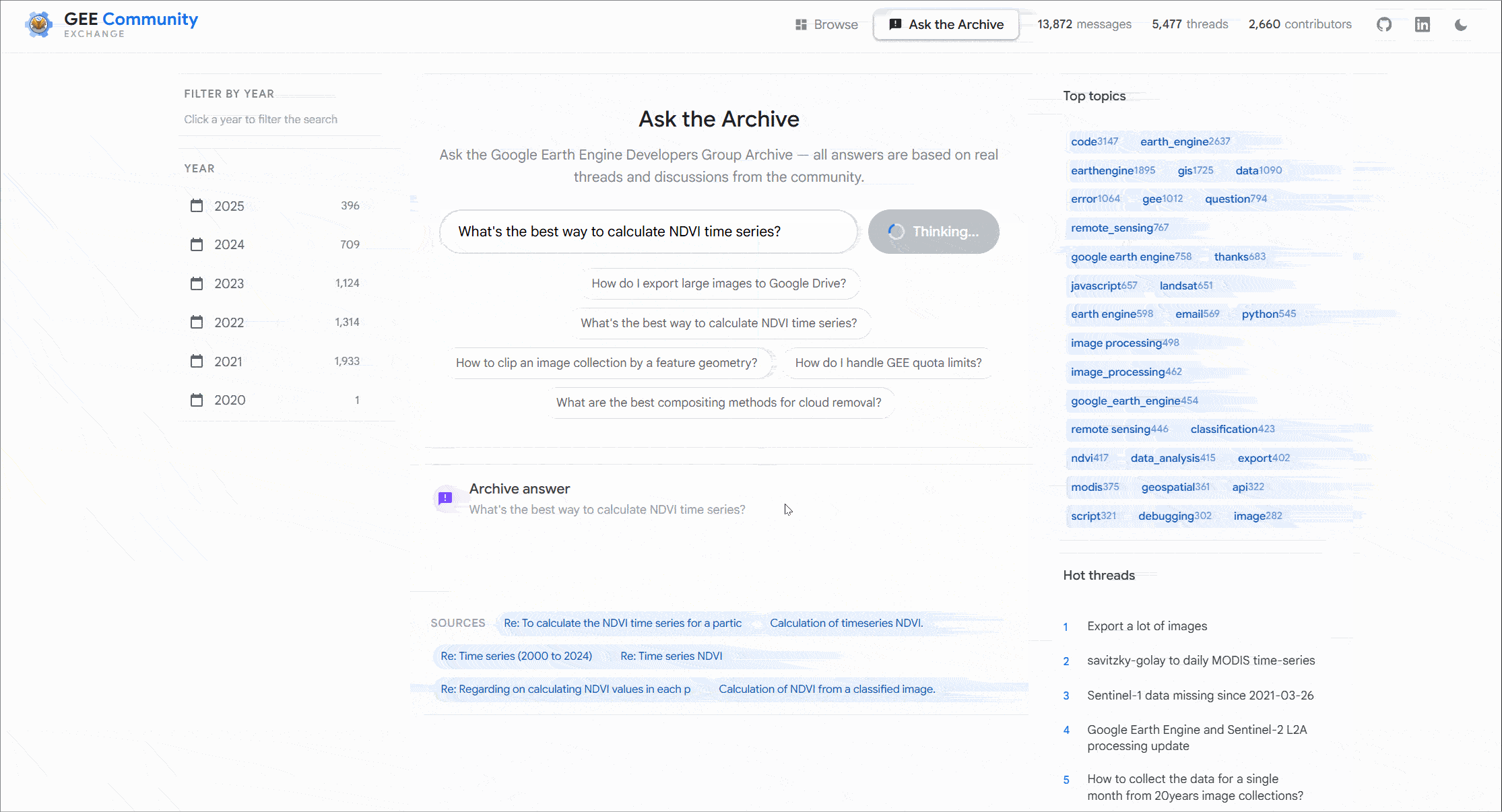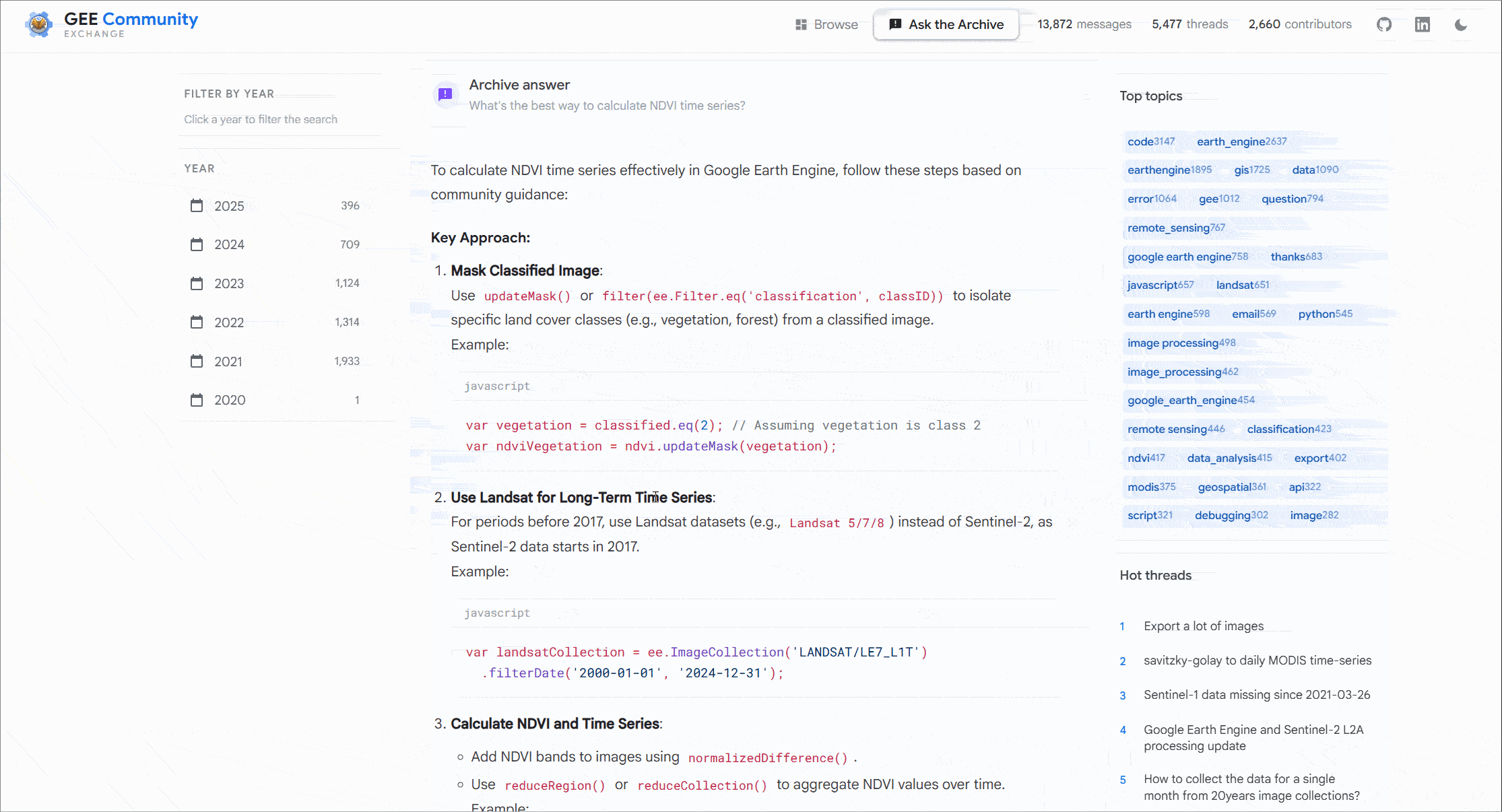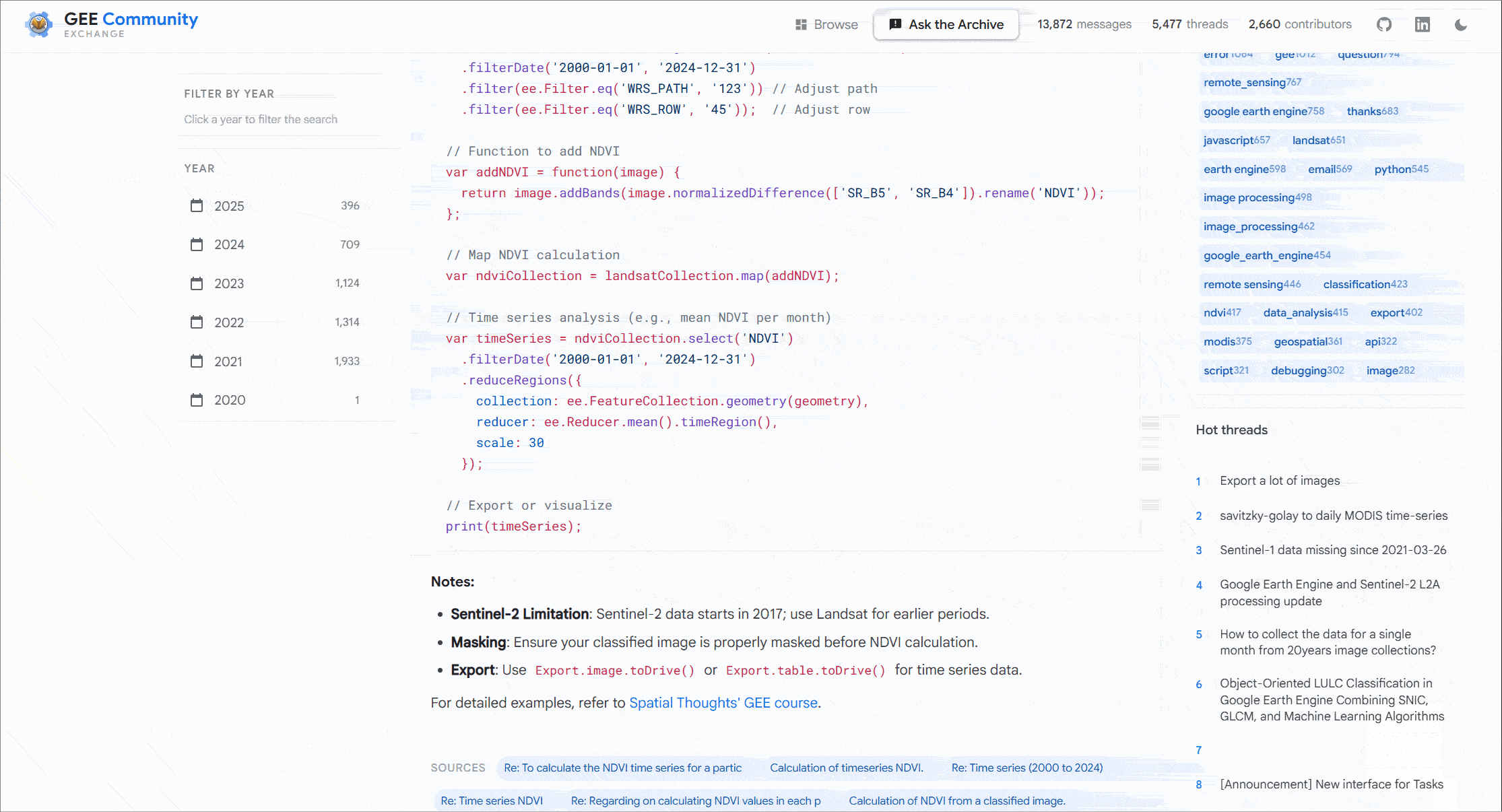
This was built to be as helpful as possible, there were design choices I made to make it performant and more importantly I wanted it to look and feel friendly from a users perspective. But here’s a quick learning remember at the core most AI models are non deterministic systems meaning just like Earth Engine EECU usage you can estimate what the answer broadly should be but the sources it chooses and the final answer could vary on every single run. This could be anything from the framing of your question to quick retrieval and so on.
Future Plans & Building More
As I mentioned before this is building using a GPU backend but it would be possible for you to do this on any machine embed the who database using Google text embedding models and then switching to Gemini API for summary and answering your final answer. I wanted to start with this because it goes beyond nostalgia of when conversations allowed people to learn but also looking at overlaps and relationships and trends, finding what worked and what caused pain. There is a lot we can learn from the community and hence the community exchange was an experiment in building out just a piece of that which I found useful. If there are others who are building things like this post a link or reach to me on LinkedIn and I would love to chat and learn. I love that we tinker as a community because we are what we build together.