
Pixels, Petabytes, and People: The Five-Year Journey of the GEE Community Catalog
Come celebrate 5 years of the Community Catalog I am revisiting how it all started and why its important for communities to build knowledge based and data commons that are relevant to them.

Five years ago, a single and simple question popped up on a Google Group for Google Earth Engine (GEE) users. A user inquired about accessing Facebook's high-resolution population density maps, a valuable dataset not present in the official GEE catalog. This simple query became the unlikely spark for an ambitious experiment: could the GEE community self organize, and help build and contribute to a shared repository of essential, analysis-ready geospatial data?

Today, the answer is a resounding yes. The Google Earth Engine Community Catalog (gee-community-catalog.org), born from that initial question, celebrates its fifth anniversary this month.

It has evolved from a single data experiment to a vital resource, hosting over 4,000 datasets encompassing over half a petabyte of information, serving over 1.5 million requests across more than 160 countries monthly. It stands as a testament to a simple, yet powerful idea: Communities are what communities build together. This is my story of its journey, and a celebration with you the community on how we build a community powered data commons in the relentless push to move from accessible data to accessibility.
Seeds of a Digital Commons
The GEE platform itself had already democratized access to petabyte-scale satellite imagery archives and cloud computing power, transforming geospatial analysis. However, many valuable datasets, particularly those generated by researchers or specialized agencies, remained difficult to use directly within GEE. They often required significant preprocessing which includes downloading, cleaning, reformatting, and uploading before analysis could even begin. If you want to take a look at anatomy of a research publication using Earth Engine and our discussions from 2023 here
I saw this gap as an opportunity. Why not ingest this dataset and many more and make it readily available as a GEE asset? This initial effort laid the groundwork for what would become the "Awesome GEE Community Catalog". The vision extended beyond simply hosting a few files. Inspired by Elinor Ostrom's work on governing the commons and the success of open-source projects like Linux and Wikipedia, the goal was to establish a digital commons for geospatial data. The catalog aimed to reduce barriers for users, providing easy access to a growing collection of public datasets under various open licenses.
It sought to mirror GEE's democratization of processing power by democratizing access to analysis-ready data, fostering a collaborative environment where shared resources benefit everyone. This philosophical underpinning, focusing on community governance and shared benefit, distinguished the project from a mere data archive from its inception. This also helped with an early realization, that communities could often inform and help prioritize requests, something you cannot get when you are building top down catalogs of data, simply put
We needed a place to say “here are the datasets we feel are important in Earth Engine and that Google and others may not.”
The catalog was designed to live alongside and complement the official Google Earth Engine data catalog, filling gaps and housing datasets frequently requested by the community.
Laying the Foundation: Infrastructure & Early Growth
Translating the vision of a community data commons into reality faced significant technical hurdles. Geospatial data, especially satellite imagery and derived products, is notoriously large and complex. Making it "analysis-ready" for GEE often involves computationally intensive tasks like making sure the data is projected properly, converted into ingestion formats accepted by GEE and taking care of image compression not to mention upload and monitoring ingest queues. The project is still an unfunded grassroots project so processing terabytes of data requested by the community presented a formidable bottleneck. Where would the necessary compute power come from?
The answer arrived through a crucial partnership with the National Science Foundation's (NSF) ACCESS program and its Jetstream & Jetstream2 cloud infrastructure, operated by Indiana University. Its allocations of millions of Service Units (CPU core hours) provided the essential horsepower

I needed to download, preprocess, clean, and ingest the growing volume of datasets. This support was not merely helpful; it was enabling. It allowed the catalog to scale from handling a single dataset request to managing hundreds, processing over 100 terabytes of data in its early years.
David Y. Hancock, principal investigator for Jetstream2, highlighted the significance of this synergy: "It's great to see our virtual cloud infrastructure used by people across the world, particularly how they can be linked with popular tools from the commercial cloud... A low barrier to entry, powerful computation resources, and minimal downtime mean that we are seeing new and innovative ways to visualize and process key datasets for both policy and research". This reliance on public cyberinfrastructure underscores its vital role in supporting community-driven open science initiatives that might otherwise lack the resources to operate at scale.
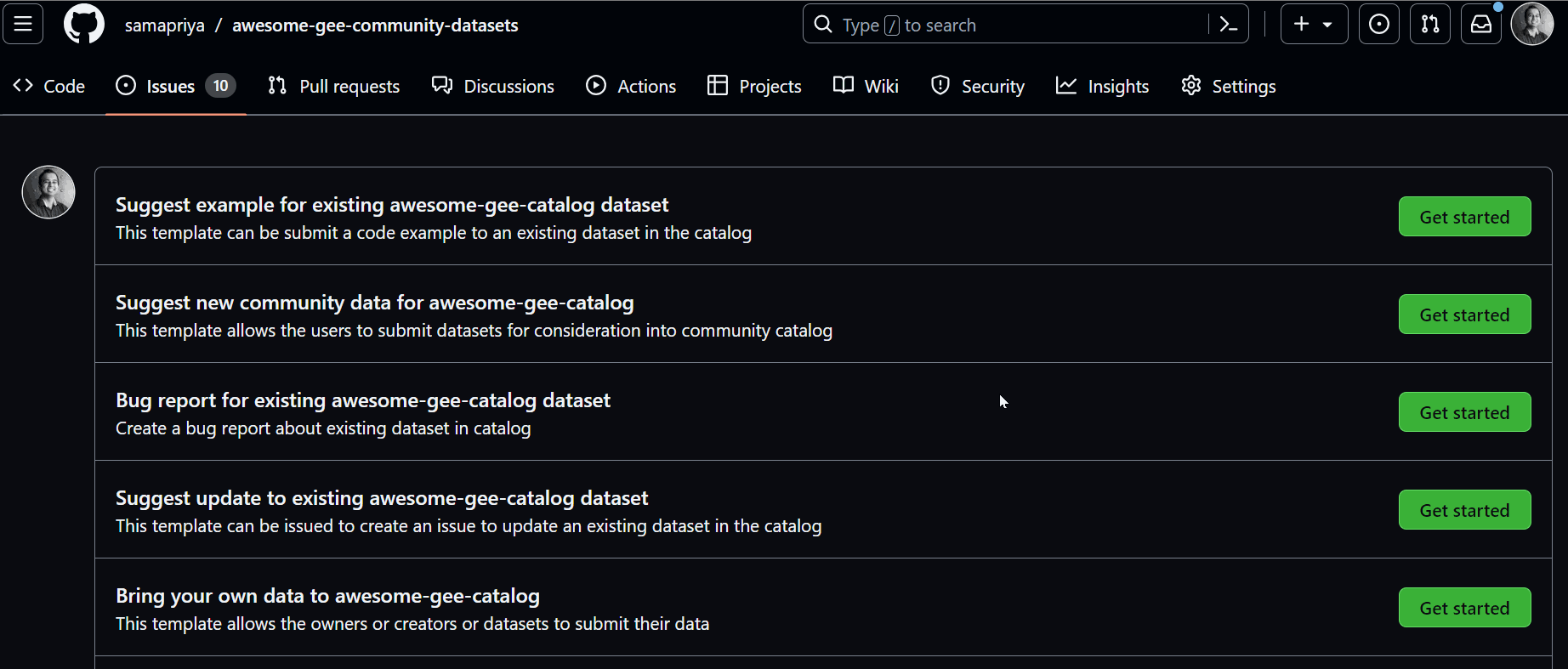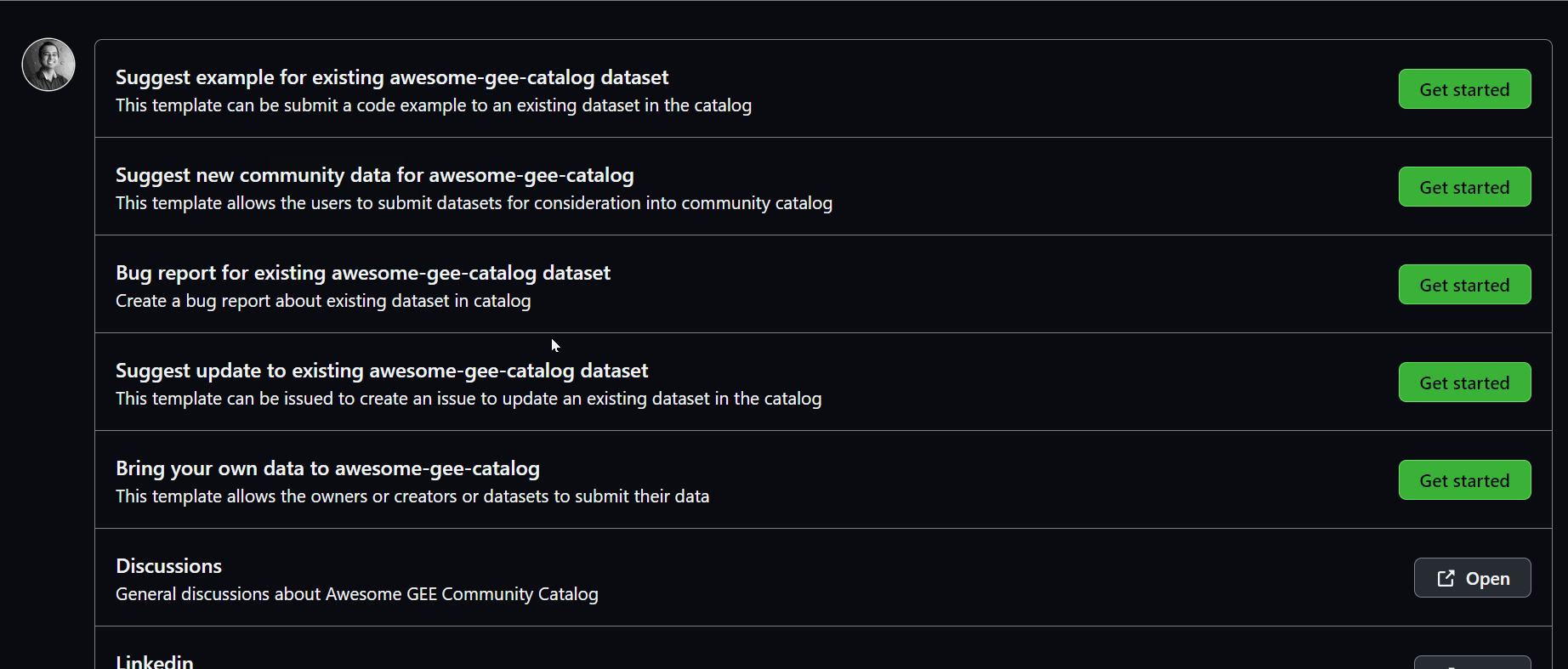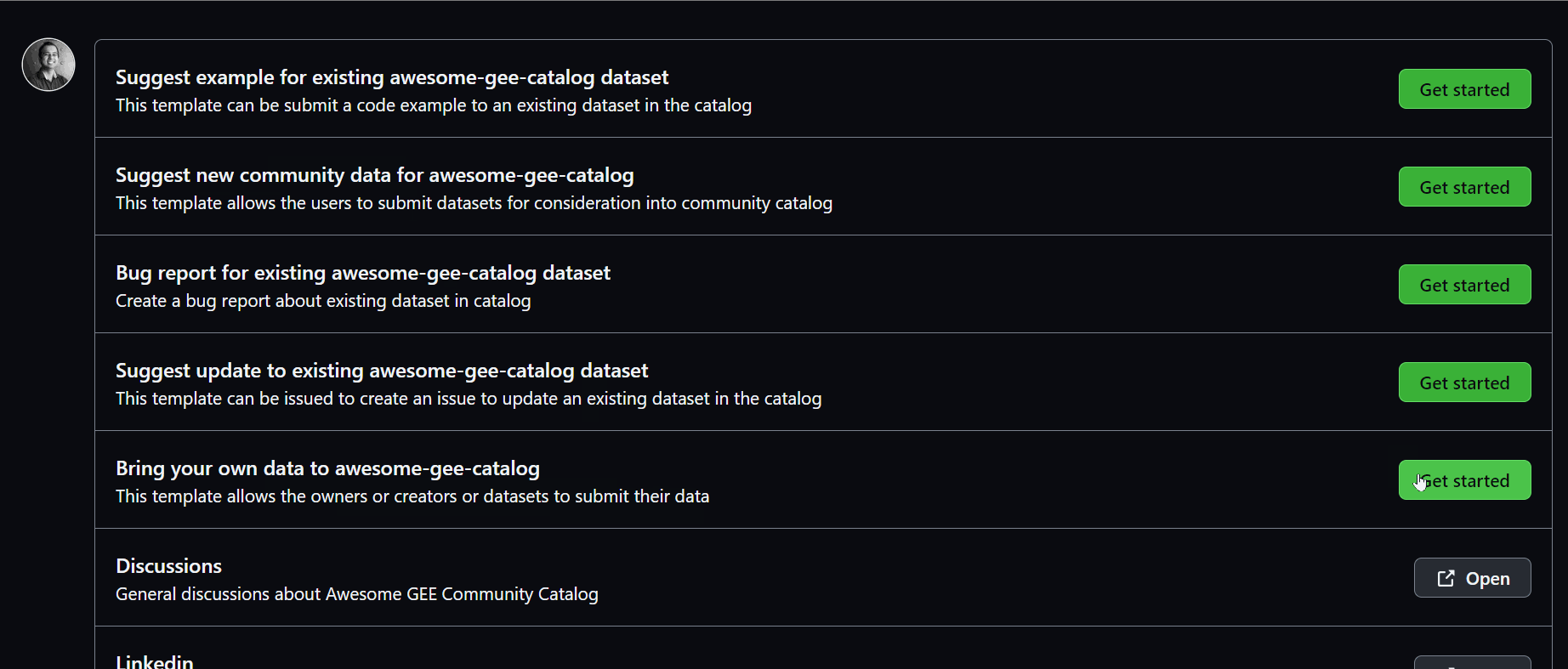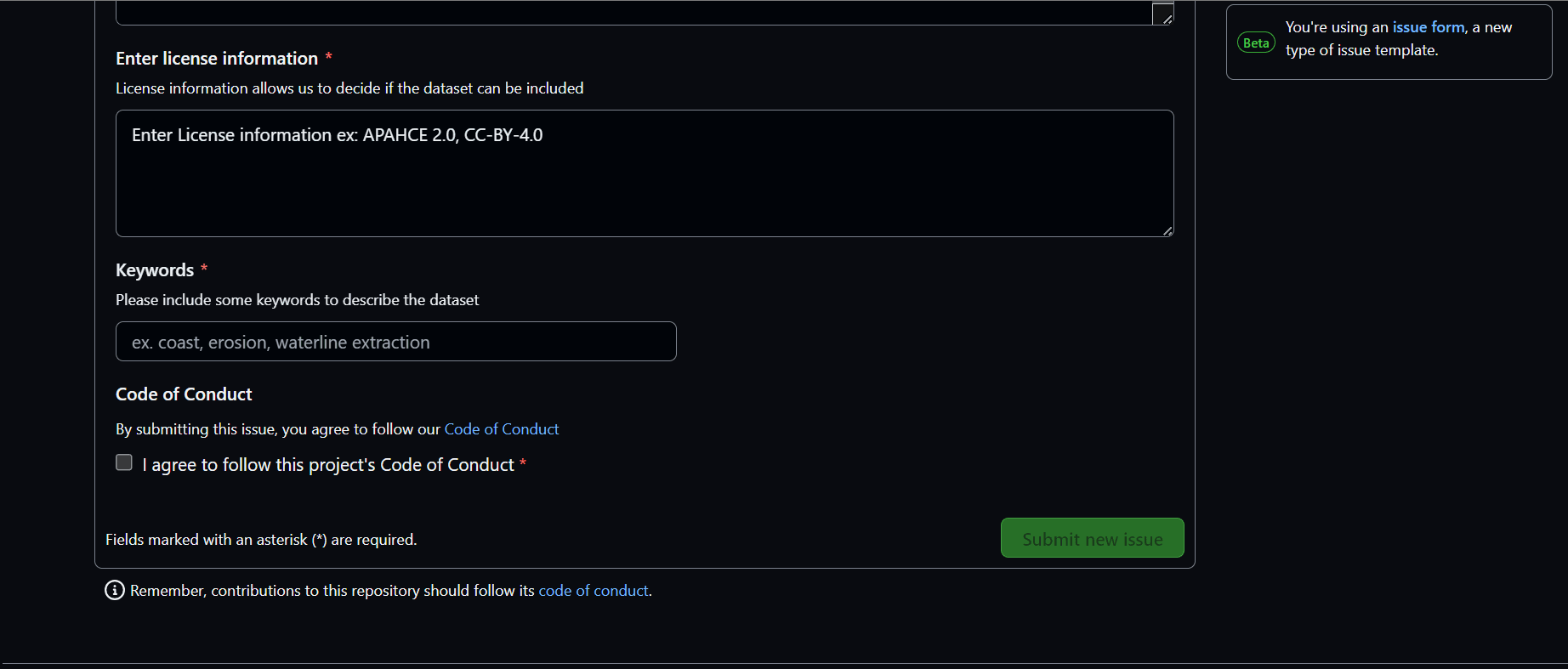
Fueled by Jetstream2's capabilities, the catalog began to grow. Community members submitted data requests via platforms like GitHub. Beyond the initial population maps, datasets covering land use, hydrology, agriculture, weather, and climate started populating the catalog. An early feedback loop developed, with users suggesting datasets, providing input, and helping to shape the resource.
The Data Floodgates Open: Scaling & Key Datasets
The combination of community demand, a clear mission, and robust infrastructure support led to a period of explosive growth. Between August 2022 and July 2023 alone, the catalog saw dramatic increases: total images grew from ~500,000 to ~850,000, image collections from ~250 to nearly 400, and total features (vector data points) doubled from ~500 million to over 1 billion. The total data volume processed and hosted surged from 104 TB to 227 TB in less than a year. Scientific data is produced and curated everyday, in different formats across different labs with different level of preparedness. The catalog was rapidly evolving into a major data catalog and users were excited. Google took notice and even included us on their earth engine pages and even introduced publisher catalogs to go along with the community effort
This expansion wasn't just about quantity; it was about the diversity and significance of the data being added. Several key additions highlight the catalog's unique value proposition and some unique ones I love include USGS historical topo maps, where we added nearly 100,000+ USGS topo maps to Google Earth Engine all the way from 1900 to 2006. You can read about it in this blog
Similar efforts brought in historical aerial imagery for the western US, sourced from over 160,000 photos dating back to the 1940s.

You can explore this and links to the images here and dataset page is here
Mapping the Human Footprint: Buildings at Scale: Understanding the built environment is critical for applications ranging from population estimation and urban planning to disaster response and environmental science. While Google released its own impressive Open Buildings dataset derived from satellite imagery, the Community Catalog also focused on integrating other major building footprint resources. Microsoft released over 777 million building footprints derived from Bing Maps imagery (later growing to over 1 billion including earlier releases). Find more in the past release
Later, the catalog added an even more comprehensive dataset curated by VIDA, which combined both the Google and Microsoft footprints, totaling over 2.5 billion buildings and covering 92% of Level 0 administrative boundaries globally. And finally we added the US Overture Maps extract as a sample dataset for evaluation.
Monitoring a Dynamic Planet: Environmental Pulse: Beyond historical maps and buildings, the catalog became a crucial hub for timely environmental data. Datasets like the U.S. Drought Monitor are updated weekly, providing a continuous pulse on drought conditions across the United States. Numerous land cover products, such as the USGS Land Change Monitoring, Assessment, and Projection (LCMAP) collection providing annual data from 1985-2021, and datasets tracking dynamic surface water extent (DSWE), were added. Water resource datasets like the SWOT River Database (SWORD) and hydrology databases became available. Climate data, including downscaled climate projections and CMIP6 model outputs, found a home in the catalog. The catalog's changelog reveals a constant influx of diverse datasets covering everything from global forest flux and field boundaries to groundwater models and air pollution.21
Getting Smarter: AI, Access, and Experience
As the catalog swelled to thousands of datasets, a new challenge emerged: discoverability. How could users efficiently find the specific dataset they needed amidst such abundance? Standard keyword searches often fall short when dealing with nuanced geospatial data descriptions and metadata.
Recognizing this, I implemented an upgrade powered with an AI-enhanced search, introduced around Release 3.0.0. Leveraging Google's Vertex AI and a technique called Retrieval-Augmented Generation (RAG), the new search function goes beyond simple keyword matching. It analyzes the content of catalog documentation pages and structured data (like JSON metadata), providing users with summarized answers grounded in the source material, complete with links for verification.
This move towards AI-powered discovery represented a necessary adaptation to maintain the catalog's usability as its scale and complexity grew, reflecting proactive development focused on the user experience.
A major step in enhancing discoverability was the launch of the GEE Community Catalog Browser.4 Conceived as a visual gateway, the browser tackles the "needle in a digital haystack" problem by allowing users to browse datasets using thumbnail previews. This provides immediate visual context about the data, complementing the traditional catalog listings. The browser integrates access to both the community and official GEE catalogs, offering advanced filtering and sorting options, direct links to documentation and code examples, user-centric features like session history and dark mode, and smooth navigation.4 Both the AI search and the visual browser demonstrate a commitment to addressing the practical challenges users face when navigating a vast and diverse data landscape.
The Commons Comes Alive: Community & Impact
Five years on, the GEE Community Catalog is far more than just a data repository. It embodies the principle of "Data with a Purpose", actively facilitating science and benefiting communities. It’s cloud native with batteries included for you to analyze data and accessibility its central goal for a global user base.
The project evolved beyond data provision to actively cultivate a community of practice. With adding tutorials and forums the catalog has transformed from a static resource into a dynamic hub for knowledge exchange and collaborative problem-solving, truly bringing the digital commons concept to life. The impact is tangible. The catalog's datasets underpin research in diverse fields, from tracking land cover change and forest health to modeling population distribution for disaster analysis. Collaborations with platforms like ClimateEngine.org, FAO SEPAL, FAO Earth Map and so many more.
The Next Five Years of Open Geospatial
The five-year journey of the Google Earth Engine Community Catalog offers a compelling case study in community-driven science. It began with a single user's need and evolved into an indispensable piece of the global geospatial data infrastructure. Its success demonstrates the power of applying commons principles to the digital realm, fostering collaboration, and leveraging community expertise to curate and share valuable resources.
The story also highlights the critical, often underappreciated, role of accessible high-performance computing infrastructure like NSF's Jetstream2. Without such support initially, the sheer computational demands of processing and hosting petabytes of geospatial data would likely have been insurmountable for a grassroots initiative.
Looking ahead, the catalog's mission remains clear: to make geospatial data accessible, analysis-ready, and useful, thereby reducing the digital divide and empowering researchers, developers, and communities worldwide. It is a living library of our planet, built pixel by pixel, petabyte by petabyte, by the very people who rely on it to understand our changing world. Its first five years have laid a remarkable foundation; the next five promise further innovation driven by the enduring power of open collaboration.
Happy Anniversary GEE Community Catalog!